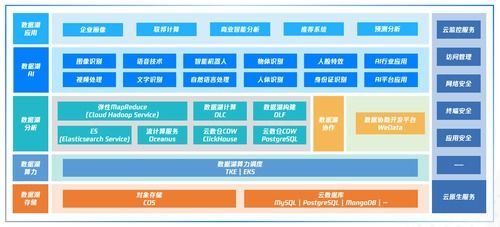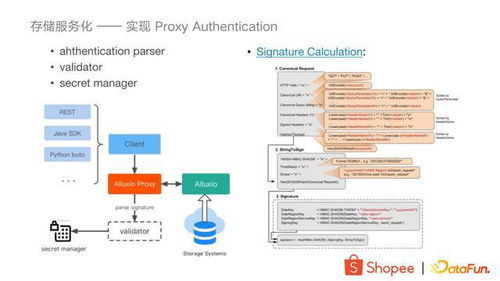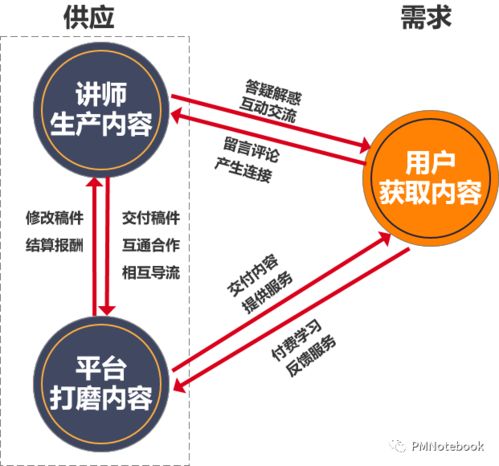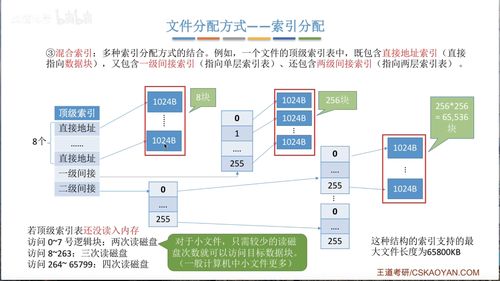
引言
在微服务架构中,数据管理是一个核心挑战。传统的集中式数据库模式在服务解耦和独立部署的需求下显得力不从心。事件驱动架构(Event-Driven Architecture, EDA)为这一难题提供了优雅的解决方案,它通过异步的事件通信,实现了服务间的松耦合与数据最终一致性。本文将深入探讨微服务中事件驱动的数据管理,特别是数据处理与存储服务的模式与实践。
一、 事件驱动数据管理的核心概念
事件驱动数据管理的核心思想是将数据的变更以“事件”的形式发布出来,其他对此感兴趣的服务可以订阅这些事件,并根据事件内容更新自己的私有数据视图或触发业务逻辑。
- 事件(Event):代表系统中已发生的、不可变的事实,例如
OrderCreated、PaymentCompleted、InventoryUpdated。 - 事件生产者(Producer):负责在业务状态变更时发布事件的微服务。
- 事件消费者(Consumer):订阅并处理事件的微服务,根据事件更新自身数据或执行业务流程。
- 事件总线/消息代理(Event Bus/Message Broker):如 Apache Kafka、RabbitMQ、AWS EventBridge 等,负责事件的可靠传递。
二、 数据处理服务的模式
在事件驱动架构中,数据处理服务扮演着消费者的角色,它们监听事件流,执行转换、聚合、丰富或计算任务。
- 数据转换与标准化:不同服务发布的事件格式可能不同。数据处理服务可以作为一个“适配器”,将原始事件转换为下游服务所需的标准化格式。
- 数据聚合与物化视图:通过持续监听多个相关事件流(如订单、物流、支付),数据处理服务可以构建跨领域的聚合数据模型(如“客户360度视图”),并将其存储为独立的物化视图。这为查询提供了单一、高效的入口,避免了复杂的跨服务联查。
- 复杂事件处理(CEP):实时检测事件流中的特定模式(如短时间内多次登录失败),并触发告警或补偿操作。
- 流式分析与实时指标计算:例如,实时计算仪表盘数据、监控业务KPI(如每秒交易量、热门商品)。
三、 数据存储服务的模式
事件驱动架构深刻影响了数据的存储方式,催生了“事件溯源”(Event Sourcing)和“命令查询职责分离”(CQRS)等模式。
- 事件溯源(Event Sourcing):
- 核心:不直接存储业务对象的当前状态,而是将其状态变化的历史记录为一个不可变的、仅追加的事件日志序列。
- 优势:
- 完整的审计追踪:所有状态变更均有迹可循。
- 时间旅行:可以重建任意历史时间点的状态。
- 解决并发冲突:事件是事实,天然避免了更新冲突。
- 挑战:需要从事件流中重建当前状态(快照机制可优化),查询复杂。
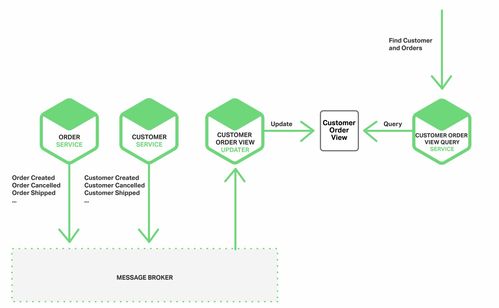
- 命令查询职责分离(CQRS):
- 核心:将修改状态的操作(命令)和读取状态的操作(查询)分离,使用不同的模型和存储。
- 与事件驱动的结合:命令端应用事件溯源,在状态变更后发布事件。查询端作为事件消费者,监听这些事件,并更新为查询优化的、独立的读模型(如关系型数据库表、文档数据库、搜索引擎索引)。
- 优势:
- 读写模型独立优化:写模型为事务和一致性设计,读模型为查询性能和灵活性设计。
- 极高的可扩展性:读写负载可以独立伸缩。
- 最终一致性:通过事件异步同步读模型,是分布式系统的常态。
- 私有数据库模式:
- 每个微服务拥有自己独立的、私有的数据库(可以是不同类型,如SQL、NoSQL)。服务间不直接访问彼此的数据库,数据共享的唯一方式是通过发布/订阅事件。这确保了服务的彻底解耦和技术异构性。
四、 实践中的关键考量
- 事件设计与版本管理:事件是公共契约,设计需清晰、稳定。必须制定策略处理事件模式的演进(如添加字段、废弃字段),通常采用向后兼容的方案。
- 数据一致性与最终一致性:接受最终一致性是分布式系统的现实。通过设计补偿事务(Saga模式)和幂等消费者来保证业务正确性。
- 可靠性与容错:确保事件至少被传递一次(at-least-once),消费者需实现幂等性处理以避免重复消费的影响。消息代理需要高可用部署。
- 监控与可观测性:建立对事件流(吞吐量、延迟)、数据处理管道健康状况以及数据一致性的全方位监控。
五、
事件驱动数据管理是微服务架构应对数据分散化挑战的利器。它将数据处理和存储从紧耦合的同步调用中解放出来,通过异步的事件流,构建出灵活、可扩展、高内聚的系统。数据处理服务专注于从事件流中提取价值,而数据存储服务则在事件溯源和CQRS等模式的指导下,实现了数据的历史性、可审计性以及读写性能的极致优化。尽管引入了最终一致性和系统复杂性的新挑战,但其为现代云原生应用带来的敏捷性和韧性,使其成为构建复杂、可演进系统的关键架构范式。