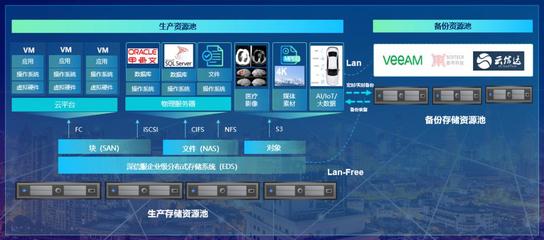
在现代应用架构中,数据处理和存储服务是支撑业务运行的核心。作为最流行的开源关系型数据库之一,MySQL凭借其成熟稳定、性能优异的特点,在众多场景中扮演着关键角色。理解其内部的数据存储与查询流程,对于数据库设计、性能优化及故障排查至关重要。本文将深入剖析MySQL从数据写入到查询返回的完整流程,揭示其作为数据处理和存储服务的工作机制。
一、 架构概览:分层的处理模型
MySQL的整体架构采用经典的分层设计,自上而下主要分为:
- 连接层:负责客户端连接管理、身份认证、安全校验等。当应用程序发起连接请求,连接层会验证用户名、密码及主机权限,并建立连接线程。
- 服务层(SQL Layer):这是MySQL的“大脑”。它包含以下核心组件:
- SQL接口:接收客户端的SQL语句(如
SELECT,INSERT)。
- 解析器:对SQL进行词法分析和语法分析,生成一棵“解析树”。
- 优化器:基于解析树、表统计信息、索引情况等,生成一个它认为成本最低的执行计划(例如,决定使用哪个索引、表的连接顺序等)。
- 查询缓存(Query Cache,在MySQL 8.0中已移除):历史上,服务层会先检查查询缓存,如果存在完全相同的SQL且数据未失效,则直接返回结果,跳过后续所有复杂步骤。
- 存储引擎层(Pluggable Storage Engine):这是MySQL架构的精髓,负责数据的实际存储和检索。MySQL支持多种存储引擎(如InnoDB、MyISAM),它们以插件形式存在,向上为服务层提供统一的调用接口。服务层通过执行计划,调用存储引擎的API来完成数据的读写。 目前,InnoDB是默认且最主流的存储引擎,支持事务、行级锁、外键等关键特性。
- 文件系统与磁盘:存储引擎最终将数据组织成文件(如表空间文件、日志文件)的形式,持久化到磁盘上。
二、 数据写入与存储流程(以InnoDB为例)
当执行一条INSERT或UPDATE语句时,流程如下:
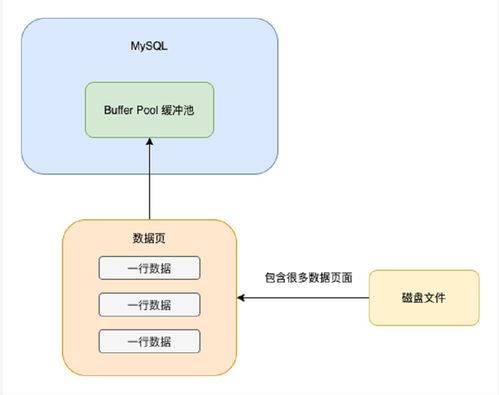
- SQL执行与缓冲:服务层的优化器生成执行计划,调用InnoDB引擎的写入接口。数据并非直接写入磁盘,而是先写入缓冲池(Buffer Pool)。缓冲池是内存中的一块核心区域,用于缓存表和索引数据,以减小磁盘I/O的延迟。
- 写入重做日志(Redo Log):为了确保事务的持久性(Durability),防止服务器崩溃导致内存中已提交的数据丢失,InnoDB会先将数据的修改内容顺序写入重做日志文件(iblogfile0, iblogfile1)。这是一个顺序写的磁盘操作,速度很快。这个过程称为 “Write-Ahead Logging (WAL)” 。
- 事务提交:当用户执行
COMMIT时,InnoDB会确保对应的重做日志条目被刷新到磁盘。一旦重做日志落盘,即使后续系统崩溃,重启后也能根据重做日志恢复数据。此时,对客户端而言,事务已经提交成功。 - 后台刷脏(Flush):缓冲池中被修改但尚未写入数据文件的数据页称为“脏页”。InnoDB有后台线程,会在适当的时候(如缓冲池空间不足、系统空闲时)将这些脏页异步地写回到磁盘上的表空间文件(
.ibd文件)中。这个过程与事务提交是解耦的,提升了整体吞吐量。 - 二进制日志(Binlog):除了存储引擎层的重做日志,MySQL服务层还会在提交前(取决于
sync_binlog配置)将数据的修改逻辑写入二进制日志。Binlog主要用于主从复制和数据恢复。
存储结构:InnoDB的表数据以聚簇索引的形式存储。表的主键(或生成的ROWID)作为索引键,与所有行数据一起存储在B+树的叶子节点中。每个表对应一个或多个独立的表空间文件。
三、 数据查询流程
当执行一条SELECT语句时,流程如下:
- SQL解析与优化:服务层解析SQL,优化器基于统计信息选择最优执行计划(例如,是全表扫描还是使用索引)。
- 调用存储引擎:根据执行计划,服务层调用InnoDB的读取API。
- 缓冲池查找:InnoDB首先在缓冲池中查找所需的数据页。如果命中(Buffer Hit),则直接从内存返回数据,这是最快的路径。
- 磁盘读取:如果缓冲池未命中(Buffer Miss),则需要从磁盘的表空间文件中将对应的数据页加载到缓冲池中,然后再返回给服务层。这个过程涉及较慢的磁盘I/O。
- 结果返回:服务层获取到存储引擎返回的原始数据行后,可能还需要进行最后的加工(如排序、聚合等,如果无法被存储引擎下推执行),最终将结果集返回给客户端。
索引的作用:索引(通常是B+树结构)是加速查询的核心。如果查询条件匹配索引,InnoDB可以快速遍历索引树定位到目标记录的主键(对于二级索引),或直接获取完整数据(对于聚簇索引),从而避免低效的全表扫描。
四、 流程中的关键优化点
- 缓冲池大小(innodbbufferpool_size):这是最重要的参数。将其设置为可用物理内存的50%-80%,可以极大提高数据缓存命中率,减少磁盘I/O。
- 合理的索引设计:基于高频查询条件创建合适的索引,避免过多或无效索引增加写入开销和维护负担。
- 事务控制:尽量使用短事务,及时提交,以减少锁的持有时间和日志刷盘压力。
- 硬件配置:使用SSD硬盘可以显著降低随机读写的延迟,尤其是对于I/O密集型的场景。
###
MySQL的数据处理流程,清晰地体现了其作为数据处理和存储服务的分工与协作:服务层专注于“逻辑”处理,负责SQL解析、优化和统筹;存储引擎层专注于“物理”实现,负责数据的高效存取、事务与并发控制。两者通过定义良好的API协同工作。理解“连接 -> 解析 -> 优化 -> 执行(缓冲池/日志/磁盘) -> 返回”这条核心链路,以及其中涉及的关键组件(如缓冲池、重做日志、索引),是进行高性能数据库应用开发、运维和调优的基石。通过优化配置、设计合理的表结构和索引,可以最大化发挥MySQL作为可靠数据存储服务的能力,为上层应用提供稳定、高效的数据支撑。