在当今数据驱动的时代,面对海量数据和高并发访问,单一数据库往往难以支撑业务发展。MyCAT(My Cluster Abstract Technology)作为一款开源的分布式数据库中间件,应运而生,旨在解决数据处理与存储服务的扩展性、可用性和性能问题。本文将从核心概念、架构设计、应用场景和实战要点四个方面,帮助你快速掌握MyCAT的精髓。
一、MyCAT的核心概念:数据分片与路由
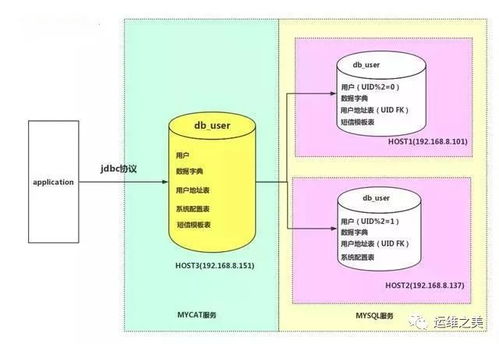
MyCAT的核心功能是数据分片(Sharding),即将一个大型数据库表水平拆分成多个小表,分布到不同的数据库节点上。它通过智能路由机制,将SQL请求转发到正确的节点,对应用层透明。例如,用户表按ID范围分片,ID 1-1000在节点A,1001-2000在节点B。MyCAT还支持读写分离,将写操作定向到主节点,读操作分发到从节点,提升整体性能。
二、架构设计:逻辑库与物理存储的桥梁
MyCAT位于应用与数据库之间,充当“代理”角色。其架构主要包括:
- 逻辑库(Schema):对应用暴露的虚拟数据库,如“user_db”,实际可能对应多个物理数据库。
- 数据节点(DataNode):定义物理数据库的连接信息,如MySQL实例。
- 分片规则(Rule):指定数据如何分布,如哈希、范围或自定义算法。
- 全局序列(Sequence):解决分布式环境下的ID生成问题,确保唯一性。
这种设计使得开发者可以像使用单一数据库一样操作,而MyCAT在后端处理复杂的分布式逻辑。
三、应用场景:何时选择MyCAT?
MyCAT特别适用于以下场景:
1. 高并发读写:如电商平台,订单表分片后,不同用户请求可并行处理。
2. 大数据量存储:日志或历史数据超过单机容量,需水平扩展。
3. 读写分离需求:读多写少的系统,通过从节点分担查询压力。
4. 多租户架构:为不同租户分配独立数据节点,实现资源隔离。
需要注意的是,对于事务一致性要求极高或复杂关联查询频繁的场景,需谨慎评估分片带来的挑战。
四、实战要点:配置与优化指南
快速上手MyCAT需关注几个关键步骤:
- 配置文件:编辑server.xml(服务参数)、schema.xml(逻辑库与节点映射)、rule.xml(分片规则)。例如,在schema.xml中定义数据节点和分片表。
- 启动与监控:通过命令行启动MyCAT,利用管理端口(默认9066)查看连接状态和性能指标。
- SQL优化:避免跨分片JOIN,尽量使用分片键查询;利用MyCAT的缓存功能减少数据库压力。
- 高可用部署:结合Keepalived或ZooKeeper实现MyCAT自身集群,避免单点故障。
MyCAT通过抽象数据存储层,为数据处理服务提供了灵活的扩展方案。掌握其分片、路由和配置核心,能有效应对数据增长带来的挑战。在实践中,建议从小规模试点开始,逐步优化分片策略,从而构建稳健的分布式存储体系。