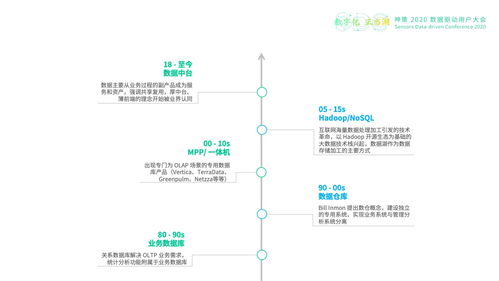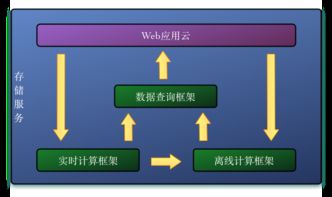
企业数据仓库建设是现代企业数字化转型的关键环节,而数据处理和存储服务则是其核心基础。本文作为系列文章的第一篇,将深入探讨数据处理和存储服务的设计要点与实施策略。
一、数据处理服务设计
数据处理服务是数据仓库的"净化器",负责将原始数据转化为可用于分析的优质数据。其设计应包含以下关键模块:
1. 数据采集与集成
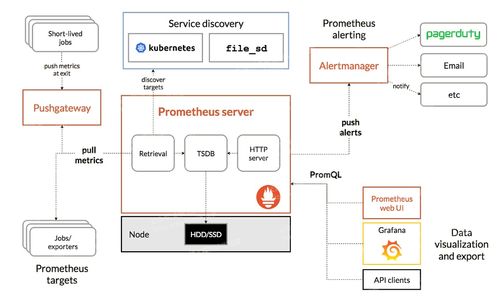
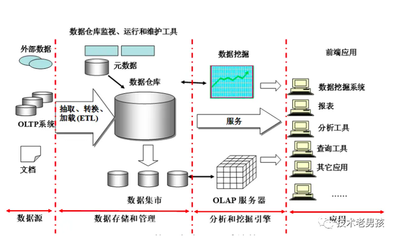
企业数据通常分散在多个业务系统中,包括ERP、CRM、OA等。设计时应采用ETL(抽取、转换、加载)或ELT流程,通过增量抽取和全量同步相结合的方式,确保数据的完整性和实时性。建议使用Apache NiFi、DataX等工具实现多源数据的统一采集。
2. 数据清洗与标准化
建立严格的数据质量监控机制,包括:
- 数据去重与补全
- 格式统一与编码规范
- 异常值检测与处理
- 数据血缘追踪
通过建立数据质量评分体系,确保进入数据仓库的数据可信可用。
3. 数据转换与加工
根据业务需求设计数据转换规则,包括:
- 维度建模(星型模型、雪花模型)
- 指标计算与聚合
- 业务逻辑封装
- 数据分层(ODS、DWD、DWS、ADS)
二、数据存储服务设计
数据存储服务是数据仓库的"保险库",需要兼顾性能、成本和安全。设计时应考虑:
1. 存储架构选择
根据数据类型和使用场景选择合适的存储方案:
- 关系型数据库(如Greenplum、ClickHouse)适用于结构化数据分析
- 数据湖(如Hadoop HDFS、对象存储)适合存储半结构化和非结构化数据
- 数据湖仓一体架构结合了两者优势
2. 分层存储策略
建立完善的数据分层体系:
- ODS层:保持原始数据,支持数据回溯
- DWD层:清洗后的明细数据
- DWS层:轻度汇总的维度数据
- ADS层:面向应用的指标数据
- 存储优化设计
- 数据分区与分桶:提高查询性能
- 数据压缩:节省存储空间
- 生命周期管理:自动冷热数据迁移
- 备份与容灾:确保数据安全
三、实施建议
- 制定统一的数据标准和规范
- 选择适合企业现状的技术栈
- 建立数据治理体系
- 考虑未来扩展性
- 重视数据安全与权限管控
数据处理和存储服务作为数据仓库的基础,其设计质量直接决定了整个数据平台的稳定性和可用性。在下一篇文章中,我们将继续探讨数据服务与应用层设计。